
Learning Spring Mass Locomotion
Bipedal locomotion is an incredibly complicated phenomena. There is so much sensory information available, ranging from perception to proprioception of the bipeds internal state. The space of actuation is massive as well, with 3D bipedal robots ranging from 10 actuators on Agility Robotics’ Cassie to 28 on Boston Dynamics’ Atlas to hundreds in the human body (defining these is an ongoing debate). This, together with the physical principles of legged locomotion leads to a hierarchical view of control. A diagram of my view of how robotic legged locomotion can be divided is shown in the image below. The levels of the hierarchy are separated by their execution rate, by the fidelity of their internal model and by the horizon for which they look ahead.
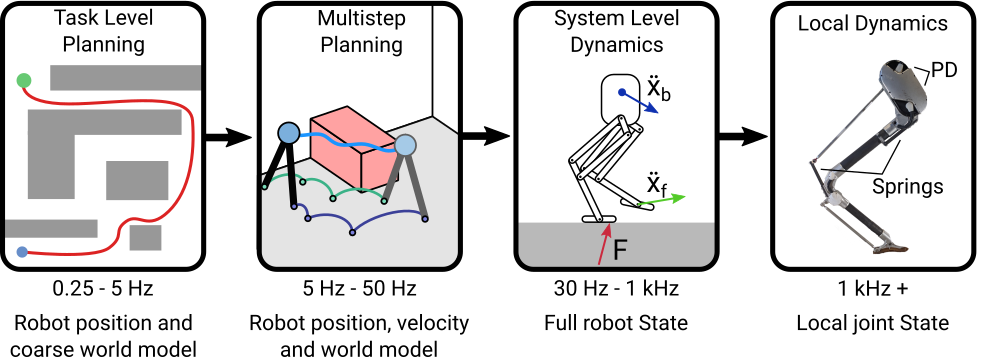
At the lowest level, we have the highest rate reactions which I call “Local Dynamics.” This contains the passive dynamics of the legged robot which we can think of as a controller that runs at an infinite rate and the local joint feedback such as PD control that run in the kilohertz. This level of control drives the immediate reaction to an unexpected disturbance such as premature ground contact or foot slip. This level of control does not have a true internal model, it is so fast that it is really just the linearized reaction of the motors to position and velocity disturbances.
One level up we have system level dynamics. To me this encapsulates whole body control methods and learned controllers from model-free RL. These methods use the whole system state and either explicitly or implicitly (through the learning process) utilize a model of the robot. This step can run at a broad range of frequencies from 30 hertz for some learned controllers to 1-2 kilohertz for efficient QP inverse dynamics. However, these methods generally don’t look forward into the future. Inverse dynamics does not at all, acting entirely in the space of instant accelerations and forces. You can argue that learned controllers implicitly are looking into the future because rewards are propagated back to previous actions. I don’t think I agree with that argument because unlike model-based RL methods, I view model-free methods as more of automatically creating very sophisticated local reactions. They are not explicitly looking to the future.
At a higher level, these methods create motion plans by looking forward into the future through multiple hybrid transitions and potentially do so with a model of the world around them. By far the most common method that fits here is receding horizon model predictive control. For bipeds this often takes the form of a linear inverted pendulum (LIP) QP planner. I hope we will see more complex or data drive models used here in the future, including model-based RL. These often run slower than the system level control methods but look forward into the future. Additionally, their model of the robot is often much simpler, such as an inverted pendulum model for bipeds or an auto-encoded state representation in a learned system.
Finally, the highest level that I am considering here is the task level planning. This is a whole field of robotics on its own. This involves creating a long term plan for how to move through a space to accomplish a goal, be that moving to a known goal, solving a maze, mapping a building or something more complex. This level runs much slower and uses a much simpler model of the robot, such as an SE(2) model with simple limits on velocity and acceleration.
In this paper, we look explore the possibility of taking a learned (model-free) controller and attempt to construct it such that it can be commanded by motions of a simplified model. The success of this will hopefully lead to the ability to interface an efficient reduced-order model multistep planner into an extremely robust learned controller. However, to focus on the learned controller and its interface we simplify the reactive reduced order planner down to a library of steady state gaits.
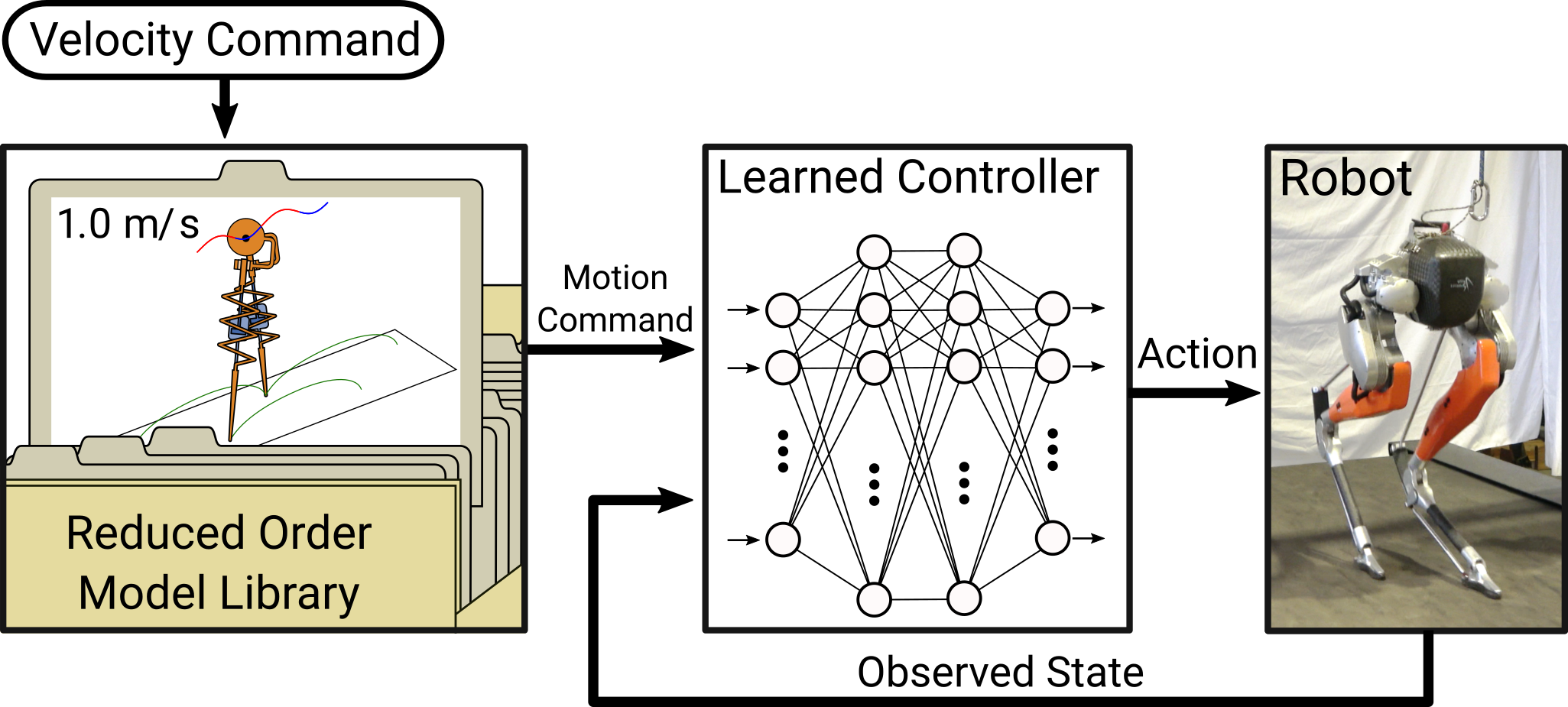
The library of gaits is built by optimizing periodic motions for a bipedal actuated spring loaded inverted pendulum model. We apply some path constraints to make sure the motions are transferable to our robot such as maximum and minimum leg length. The objective for this optimization is integrated torque squared on the actuator. In principle this makes sense as an objective because if the actuators in this model were electric motors, this would represent the power lost to restive heating in the windings. It ignores the torque that would be required to accelerate the motor inertia and the cost of work done by the motor, but it creates reasonable trajectories for the library. In a real reactive planner we would certainly have to simplify the actuator command which would create less than energetically optimal actuation patterns so the motion planning would be real-time viable.
Once we have our library of motions we can plug them into our control structure that surrounds the learned controller. The controller is a 256 by 256 standard feed-forward neural network. We train it using PPO and our MuJoCo simulation of Cassie. Importantly, 70% of the reward function is based on how well the resulting motion matches the motions from the reduced-order model library. This means that it is both being commanded by and rewarded through the simplified model motions.
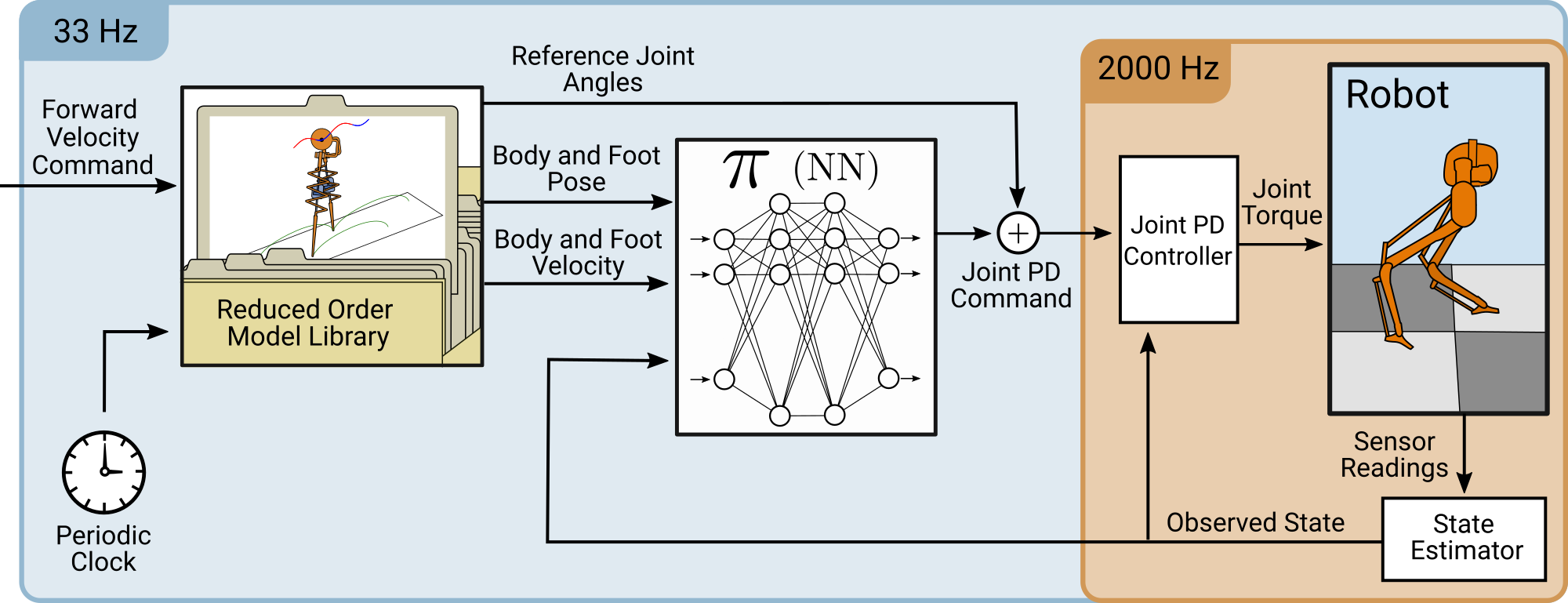
This results in a learned controller that transfers reliably from simulation to hardware and exhibits many features of the motions of the reduced-order model. Hardware trials are shown in the video at the top of the page. The full ICRA presentation of this work is shown in the video below.